BLOG

デジタル化の時代において、情報技術はあらゆる生産および事業活動の基盤となっている。しかし、包括的な社内ITチームを維持することはしばしば高コストであり、柔軟な拡張が難しく、急速に変化する技術のスピードに追随することも容易ではない。そのため、ITアウトソーシングはますます一般的な戦略となっており、企業が高度な専門リソースにアクセスし、コストを最適化し、導入時間を短縮し、コア業務に集中することを可能にしている。多くの市場調査によれば、ITサービスおよびアウトソーシングへの世界的な支出は継続的に成長しており、特にクラウドコンピューティング、サイバーセキュリティ、インフラ管理サービスの分野で顕著である。これは、企業がもはやアウトソーシングを単なるコスト削減策としてではなく、イノベーションとデジタルトランスフォーメーションを推進するレバーとして捉えている現実を反映している。しかし、機会と並行してリスクも存在する。誤ったパートナー選定、契約の不透明さ、または初期段階での不明確なスコープ定義により失敗するプロジェクトも少なくない。このような状況において、Request for Proposal RFP は、企業が選定および協業プロセス全体を体系化し透明化するための標準化されたツールとなる。RFPは単なる入札招請書ではなく、戦略的な指針文書であり、企業がニーズ、業務範囲、評価基準を明確に記述することを可能にすると同時に、ベンダーが適切なソリューションを提案するための条件を整える。実務上、アウトソーシングプロジェクトの半数以上が不明確または標準化されていないRFPに起因する問題に直面していることが示されており、効果的なRFPがITアウトソーシング成功の決定的要因であることを裏付けている。 ITアウトソーシングにおけるRFPの戦略的役割 RFPは企業とITサービスプロバイダーをつなぐ架け橋として機能し、初期段階から双方の期待と協業範囲を一致させる役割を果たす。技術要件のみに焦点を当てるのではなく、効果的なRFPは組織全体のビジネス目標を反映する必要がある。なぜなら、最終的にあらゆる技術ソリューションは長期的な発展戦略に資するものでなければならないからである。RFPが顧客体験の向上、運用効率の改善、市場拡大といった目標と密接に結び付いている場合、ベンダーは自らが単なる個別の技術プロジェクトではなく戦略的イニシアチブに参加していることを理解する。これにより企業はコスト比較だけでなく、創出される価値に基づいて提案を評価できる。同時に、RFPは回答の標準化を促進し、契約リスクを低減し、選定プロセスの透明性を高める。明確で論理的な構造と具体的な評価基準を備えた文書は、ベンダーが提案ソリューションに真剣に投資することを促す一方、曖昧なRFPは一般的で深みのない比較困難な回答につながりやすい。 機会およびプロジェクト範囲の明確な記述 効果的なRFPは、アウトソーシングの機会と企業の現状背景を詳細に記述しなければならない。ITアウトソーシングにおける機会は、ソフトウェア開発、企業資源計画システムの導入、クラウドインフラ管理、または長期的な技術サポートサービスの提供などが考えられる。記述があまりにも一般的である場合、ベンダーは正確なソリューションを提示することが困難となり、導入時に契約外費用が発生しやすくなる。単に概括的なニーズを述べるのではなく、現在使用しているシステム、統合要件、想定ユーザー数、性能基準、将来の拡張計画、データに関連する法的制約を明確にするべきである。RFP作成過程において業務部門、財務部門、法務部門からの意見を参照することは、プロジェクト範囲が実際のニーズを十分に反映していることを確保するのに役立つ。初期段階で範囲が正確に定義されていれば、遅延や追加コストのリスクは大幅に低減される。 具体的な回答要件と透明な評価モデル 優れたRFPは比較可能性と客観性を確保するために回答構造を明確に規定する必要がある。企業はベンダーに対し、ソリューション概要、拡張性と統合性を含むシステムアーキテクチャ、人員計画と適切なリソース配分モデル、主要マイルストーンを含む導入ロードマップ、サービスレベルコミットメント、プロジェクト管理体制、進捗報告方法を提示するよう求めるべきである。さらに、価格算定方法、対象範囲、要件変更時の調整条件を含むコストモデルも明確にする必要がある。実務上、最低価格のみに基づいてベンダーを選定することは、技術的欠陥、遅延、運用の柔軟性不足により総保有コストが高くなる結果を招くことが多い。そのため、技術能力、業界経験、イノベーション能力、文化的適合性、長期的総コストを含む多基準評価モデルを適用すべきである。評価基準とその重み付けがRFPで明確に公開されていれば、選定プロセスはより透明になり、主観的要素が最小化される。 回答期間と実証試験の重要性 IT分野のRFPへの回答は、ベンダーが要件分析、ソリューション設計、リソース算定を行う必要があるため、一般的な物品調達よりもはるかに複雑である。合理的なタイムラインには、RFP発行日、質疑応答期間、提案提出期限、評価期間、プロジェクト開始予定日を含めるべきである。期間が過度に短い場合、ベンダーは十分に深く包括的な提案を行うことができず、導入リスクが高まる。大規模システム導入やインフラ移行などの複雑なプロジェクトでは、本契約締結前に小規模な実証試験を要求することを検討すべきである。この試験形式は実際の能力を検証し、既存システムとの適合性を評価し、技術的リスクを早期に発見するのに役立ち、後の修正コストを最小化する。 RFPテンプレートの標準化とセキュリティおよびコンプライアンス要件 標準テンプレートを使用することで、複数回の発行においてもRFPの専門性と一貫性を維持できる。ITアウトソーシングにおいては、データ保護、知的財産権、サポートおよび保守、必須技術基準に関する条項を含めるべきである。特にセキュリティと法令遵守は極めて重要な要素である。企業はベンダーに対し、国際的に認知された基準に基づく情報セキュリティ管理能力の証明、ITリスク管理プロセス、アクセス制御、データ暗号化、インシデント対応計画の説明を求める必要がある。国際市場で事業を行う場合には、該当するデータ保護規制の遵守コミットメントも要求すべきである。これらの要件を初期段階から統合することは、法的リスクを低減するだけでなく、長期的にブランドの信頼性を保護する。 リスク管理と契約終了戦略の統合 リスク管理はRFP構造の不可欠な一部と見なされるべきである。企業はベンダーに対し、技術的リスク、運用リスク、ベンダー依存リスクの特定と軽減方法を提示させるとともに、知識移転メカニズムおよび契約終了時の引き継ぎ計画を説明させるべきである。契約終了戦略は不信の表れではなく、あらゆる状況において企業がデータとシステムの管理権を維持するための専門的なガバナンス実務である。これらの要素がRFPで明確に規定されていれば、協力関係はより透明で持続可能なものとなる。 長期協業における関係管理と文化的要素 優れたRFPは選定段階だけでなく、契約締結後の関係管理の基盤も築く。企業は双方の管理体制、定期報告メカニズム、パフォーマンス評価プロセス、継続的改善メカニズムの説明を求めるべきである。さらに、文化およびコミュニケーションの要素もITアウトソーシング成功において重要な役割を果たす。業務スタイル、タイムゾーン、管理手法の違いは、事前に想定されていなければ対立を引き起こす可能性がある。RFP段階で文化的適合性とコミュニケーション能力を評価することは、摩擦を減らし、協働効率を高め、双方の信頼を構築するのに役立つ。 イノベーション能力と持続的発展の確保 デジタルトランスフォーメーションの時代において、企業は単なる実行ベンダーではなく、イノベーションを共に推進できるパートナーを求めている。そのため、RFPでは新技術活用能力、長期的発展ロードマップ、継続的改善へのコミットメントの提示を求めるべきである。イノベーション能力が評価基準の一つとして扱われることで、企業は現在のニーズを満たすだけでなく、将来の変化にも適応できるパートナーを選択する機会を得る。 結論 ITアウトソーシングにおいて、RFPは単なる入札文書ではなく、適切なパートナーを選定し持続可能な協業基盤を確立するための戦略的ツールである。明確で詳細かつ合理的な構造を備えたRFPは、ニーズを正確に特定し、回答を標準化し、導入リスクを低減し、評価の透明性を確保するのに役立つ。複数部門の参加のもとでビジネス戦略と密接に連動して構築されたRFPは、アウトソーシングプロセスを最適化するだけでなく、ITアウトソーシングをイノベーションと長期的発展を促進する原動力へと転換させる。 続きを読む:

Third Party Risk Management TPRMは、この10年以上の間に大きく変化してきました。以前は、この活動は主に特定時点でのチェックを行うものであり、コンプライアンス要件を満たすためのチェックリストに基づいて実施されていました。現在では、Third Party Risk Managementはエンタープライズレベルの戦略的なリスク管理能力となりつつあり、リアルタイム運用に近づき、より明確なビジネス価値を生み出しています。 この変化は規制圧力だけでなく、パートナーエコシステムがますます複雑になっている現実からも生じています。米国のOCCやバーゼル銀行監督委員会などの主要な金融規制当局のガイダンスによれば、企業は第三者リスクを定期的な評価ではなく、データに基づいて継続的に監視する必要があります。意思決定を支援できる継続的なTPRMモデルへ移行するために、組織はデータ品質の低さ、部門間のサイロ化、過度に重い統制プログラム設計といった中核的なボトルネックを解決する必要があります。 THIRD PARTY RISK MANAGEMENTの高度化における規制とグローバルインシデントの役割 多くの規制当局が第三者管理に関する最新ガイダンスを発行した後、Third Party Risk Managementはリスクガバナンスの中心的な位置に戻りました。近年のサプライチェーンの混乱、データ漏えい、大規模なサイバー攻撃は、ベンダーからのリスクが広範囲に波及し、システム全体に影響を与える可能性があることを示しています。 多くの組織はTPRMプログラムの範囲を拡大し、パートナーのリスク階層化を適用し、経営陣および取締役会への報告を強化し、基本的なサプライヤー一覧を超えた監視を実施しています。技術サプライチェーンリスク管理に関するNISTの推奨によれば、重要なサプライヤーと依存関係を特定することは、運用レジリエンスを高めるための重要な要素です。 この高度化プロセスの結果として、企業はサプライチェーンに対する可視性を高め、重要な関係をより正確に特定し、契約条件を改善し、高リスク環境における事業継続能力を強化しています。 継続的データと人工知能に基づくリアルタイムTPRM 現代の運用モデルはリアルタイムで動作しているため、定期的なリスク評価だけでは新たな脅威を発見するには不十分です。現代のThird Party Risk Managementは、財務開示、制裁リスト、サイバーセキュリティ警告、インシデントデータ、メディアニュース、サプライチェーンシグナルなど、多様な情報源からの継続的なデータ収集に基づく必要があります。 サプライヤー関係におけるセキュリティを扱うISO 27036などの情報セキュリティ分野の優良実践基準も、一度限りの評価ではなく継続的な監視を強調しています。データが頻繁に更新されることで、組織はリスクをより早期に検知し、実際の影響度に応じて対応することが可能になります。 人工知能は現代のTPRMにおいて重要な支援ツールの役割を果たします。AIは複数のシステムからデータを統合し、異常なパターンを識別し、傾向を予測し、リスクの優先度を順位付けする能力を持ちます。その結果、リスク管理チームは分散的に処理するのではなく、影響の大きい問題に集中できます。 TPRMの基盤となるデータの標準化とクレンジング Third Party Risk Managementの有効性に対する大きな障壁の一つは、過去データの品質が低いことです。ベンダーおよびサプライヤーに関する情報は、しばしば古く、不整合であり、調達システム、契約管理プラットフォーム、GRCシステム、財務システムの間に分散しています。 DAMA Internationalのエンタープライズデータガバナンスガイドラインによれば、管理されていないデータは分析および予測モデルの信頼性を低下させます。TPRMの文脈では、低品質データは手作業の繰り返し処理を引き起こし、評価結果の信頼性を損ない、AIモデルの出力を歪めます。 継続的な監視を支えるために、企業はデータクレンジングへの投資、分類体系の標準化、共通データ辞書の確立、長期的なデータガバナンス体制の構築を行う必要があります。データガバナンスは一度限りの活動ではなく、運用能力にならなければなりません。 調達、法務、TPRMの間のサイロの解消 多くのThird Party Risk Managementプログラムは、事業部門、調達、法務、リスク管理などの部門間のサイロによって依然として困難に直面しています。各部門は異なる目標、評価指標、スケジュールを持っているため、引き継ぎの遅延、契約サイクルの長期化、商業目標とリスク統制目標の対立が生じます。 グローバル内部監査人協会のThree Linesモデルに基づく優良実践は、リスクガバナンスを承認プロセスの最後に置くのではなく、業務プロセスに組み込むことを推奨しています。企業はTPRM要件をサプライヤー選定プロセスに直接組み込み、契約条件をリスク階層レベルと連動させ、部門間で共通のKPIを構築すべきです。 指標とエスカレーションの仕組みが整合されると、第三者リスク管理は後工程の障壁ではなく、商業的意思決定の一部になります。 過度に複雑で統制過多なTPRMプログラム設計を避ける Third Party Risk Managementは、情報セキュリティ、プライバシー、コンプライアンス、財務リスク、運用リスクなど、多くの領域を対象とします。範囲を統制しなければ、プログラムは重くなり、重複した統制や過度に長い質問票を伴うものになりがちです。 内部統制の有効性に関する研究は、統制の過多が実際の遵守レベルを低下させ、プロセス回避行動を助長する可能性があることを示しています。TPRMが過度に複雑になると、業務活動は遅くなり、サプライヤーは評価対応に疲弊し、事業部門のリスクオーナーシップは低下します。 バランスの取れた解決策はリスクベースの自動化です。低リスクの評価は自動化されるべきです。AIは重要なリスクを抽出し優先順位付けするために活用されるべきです。人間の専門家は判断が必要な意思決定に集中すべきです。第二線および第三線の監視活動は、プログラム資源を消耗させないように、レビューの頻度と深度を適切に調整する必要があります。 継続型TPRMへ高度化することによるビジネス上の利点 データ、サイロ、複雑性の問題が解決されると、Third Party Risk Managementプログラムは明確なビジネス価値を生み出すことができます。リアルタイムTPRMモデルは、調達およびサプライヤーオンボーディングのサイクルを短縮し、インシデントの検知と是正を加速し、コスト管理と運用効率を支援します。 COSO ERMなどの現代的なエンタープライズガバナンスフレームワークも、リスクガバナンスを価値創出と結びつけることを強調しています。データ品質が高く、AIが適切に活用され、部門間の連携が取れ、プログラムが適切な規模で設計されている場合、Third Party Risk Managementはコンプライアンスチェックポイントから継続的な予測能力へと進化を完了し、企業価値を保護し、持続的な成長を支援します。
なぜアーキテクチャがデジタルプロダクトの生存を左右するのか デジタル時代において、多くのプロダクトが失敗する理由は、アイデアの魅力が不足しているからではなく、初期段階を超えて成長できないことにある。迅速に構築されたMVPはスタートアップが市場に早く参入する助けとなるが、ユーザー数が増加したときにそのプロダクトが拡張可能かどうかを最終的に決定するのはソフトウェアアーキテクチャである。開発段階ごとに適切なアーキテクチャ戦略を欠いていると、多くのチームがシステム全体を書き直さざるを得ない状況に陥り、時間とコストを浪費し、競争優位性を失うことになる。 MVPからScalable Productへのテーマは、純粋な技術論にとどまらず、プロダクト思考、ビジネス戦略、そして技術的能力が交差する領域である。ソフトウェアアーキテクチャは最初から固定された決定として捉えるべきではなく、プロダクトの成熟度や市場の実際のニーズに密接に沿った、意図的な進化のプロセスとして考える必要がある。 MVP段階 速度と学習を支えるアーキテクチャ MVP段階において最も重要な目的は、完璧なシステムを構築することではなく、可能な限り短い時間でプロダクト仮説を検証することである。MVPは、ユーザーが本当にこの問題を抱えているのか、現在の解決策が継続的に利用されるほど魅力的かどうか、そしてユーザーが支払う意志や長期的に利用する意志があるかどうかといった、極めて重要な問いに答えるために存在する。 そのため、MVPのアーキテクチャは拡張性よりも意思決定のスピードを重視すべきである。シンプルで理解しやすく、修正しやすいアーキテクチャは、チームが迅速に実装し、実験し、必要に応じて変更することを可能にする。多くの場合、モノリシックなアーキテクチャはMVPにとって合理的な選択であり、開発チームがすべてのロジックを単一のシステムに集中させることができ、運用コストや導入の複雑さを抑えることができる。 しかし、シンプルなアーキテクチャを選択することは、方向性のないコードを書くことを意味しない。適切に構築されたMVPであっても、ユーザーインターフェース、業務ロジック、データアクセスといった各層の間に一定の分離を保つ必要がある。これにより、コードベースが混乱するのを防ぎ、プロダクトが成長し始めた際の再構築に向けた土台を作ることができる。 この段階でよくある誤りは、最初から数百万人のユーザーを想定してシステムを設計しようとすることである。実際のユーザーが存在しない段階で拡張性を過度に最適化すると、リリースが遅れるだけでなく、現実的な根拠のない技術的仮定にチームが囚われてしまう。 転換点 MVPでは不十分になるとき MVPから拡張可能なプロダクトへ移行する理想的なタイミングが明確に存在するわけではない。しかし、現在のアーキテクチャが成長の障害になり始めていることを示す明確な兆候は存在する。コードベース内の依存関係が複雑化し、機能開発の速度が低下したとき、デプロイのたびにシステム全体の障害リスクが高まるとき、あるいは負荷の増加によりパフォーマンスが明らかに低下し始めたとき、それはアーキテクチャを真剣に見直すべき時期である。 この移行段階は将来の拡張コストを左右するため、極めて戦略的な意味を持つ。再構築を早く行いすぎると、まだ存在しない問題に対してリソースを浪費する可能性がある。一方で、あまりにも長く先延ばしにすると、技術的負債は指数関数的に増大し、最終的には複雑でリスクの高い大規模改修を余儀なくされる。 この段階で最も重要なのは、直感ではなく実際のデータに基づいてアーキテクチャを評価することである。パフォーマンス指標、機能の利用状況、エラー発生頻度、ユーザーからのフィードバックを体系的に分析し、本当に解決すべきボトルネックがどこにあるのかを特定する必要がある。 初期拡張段階 プロダクトが市場価値を証明し、安定した成長を始めた段階では、アーキテクチャも拡張ニーズに対応できるよう調整する必要がある。この段階では、モノリシックな構造からモジュールまたはサービス単位に分割されたアーキテクチャへと段階的に移行することが合理的な選択となる。 システム全体を一度に分割するのではなく、重要な業務ドメインを特定し、優先順位に基づいて切り出す方が効果的である。利用頻度が高い機能や、独立した拡張が求められる機能は、最初にサービスとして分離される候補となる。このアプローチにより、コアシステムの負荷を軽減しつつ、各コンポーネントを独立して最適化およびデプロイできるようになる。 サービス指向アーキテクチャは技術的な利点だけでなく、組織面でも大きな効果をもたらす。各チームが明確な業務ドメインに責任を持つことで、開発スピードとプロダクト品質は大きく向上する。 ただし、マイクロサービスアーキテクチャの導入には新たな課題も伴う。サービス間通信、分散データ管理、システムの可観測性はより複雑になる。そのため、このアーキテクチャは、十分な経験と適切な運用プロセスを備えたチームであってこそ、本来の効果を発揮する。 SCALABLE PRODUCT プロダクトがスケーラブルであるとは、ユーザー数、データ量、機能が増加しても、パフォーマンスやユーザー体験を大きく損なうことなく成長できることを意味する。この段階では、アーキテクチャは単なる耐荷重性だけでなく、市場の急速な変化に対応できる柔軟性も備えていなければならない。 クラウドネイティブやイベント駆動といった現代的なアーキテクチャは、持続可能な拡張基盤を構築する上で重要な役割を果たす。クラウドインフラを活用することで、システムは実際の需要に応じてリソースを自動調整でき、運用コストを削減し、障害に対する耐性を高めることができる。一方、イベント駆動アーキテクチャは、システム内の各コンポーネントが非同期に連携することを可能にし、依存関係を減らしながら複雑な業務フローの処理効率を向上させる。 大規模な環境では、データ管理は戦略的な課題となる。書き込みと読み取りのフローを分離し、クエリ最適化モデルやデータ分割を適用することで、データ量が急増しても高いパフォーマンスを維持できる。これは、プロダクトが技術的に拡張するだけでなく、安定したユーザー体験を保つための重要な要素である。 段階別アーキテクチャ戦略 MVPからScalable Productへと進む過程における最も重要な教訓の一つは、アーキテクチャを最初から完璧に設計しようとしないことである。その代わりに、進化的な思考を持ち、プロダクトの成長段階に応じて変化し適応できるように構築する必要がある。 MVPの一時的な制約を受け入れることで、チームは市場から学ぶことに集中できる。プロダクトが成長するにつれて、アーキテクチャはデータと明確なビジネス目標に基づき、意図的に調整されるべきである。エンジニアリング、プロダクト、ビジネスの各チームが密接に連携することが、すべてのアーキテクチャ移行が実質的な価値を生み出すための決定的な要因となる。 結論 MVPから拡張可能なプロダクトへ至る道のりは、ビジョン、規律、そして柔軟性を必要とする長いプロセスである。ソフトウェアアーキテクチャは単なる技術基盤ではなく、リソースの最適化、リスクの低減、そして持続可能な競争優位性を築くための戦略的な手段である。 適切に構築されたMVPは、アイデアを迅速に検証することを可能にする。開発段階ごとに適したアーキテクチャ戦略は、プロダクトの安定した成長と長期的な拡張への備えを支える。アーキテクチャを固定的な決定ではなく進化のプロセスとして捉えるとき、プロダクトはデジタル経済の激しい競争環境において、より高い成功確率を得ることができる。 続きを読む:

デジタル時代において、ソフトウェアはもはや単独の技術製品ではなく、企業、政府、そして世界経済全体を支える運用基盤となっている。現在の多くの重要なシステムは、銀行、医療、物流から公共サービスに至るまで、ソフトウェアに依存している。しかし、その急速な発展と並行して、長い間あまり注目されてこなかった現実が存在する。それは、現代のソフトウェアが、開発企業自身が直接管理していない無数の外部コンポーネントから構築されているという事実である。 この透明性の欠如という空白から、SBOMが生まれ、ソフトウェアセキュリティとデジタルサプライチェーンに関する議論の中で急速に中心的な概念となった。もはや単なる技術的な推奨事項ではなく、SBOMは国際市場に参加するソフトウェアにとって、徐々に必須の標準となりつつある。 現代ソフトウェアと内部の透明性不足という課題 今日のソフトウェアの顕著な特徴の一つは、オープンソースコードやサードパーティのライブラリへの依存度が非常に高いことである。一般的な企業向けアプリケーションは、数百種類の異なるライブラリを使用することがあり、それぞれのライブラリがさらに多くの間接的な依存関係を伴っている。これは開発期間の短縮、コスト削減、コミュニティの知識の活用に役立つ一方で、ソフトウェアの構造を極めて複雑なものにしている。 長年にわたり、この複雑さは技術チームの内部領域に完全に収まっていたため、大きな問題とは見なされてこなかった。顧客はソフトウェアが正しく動作するかどうかだけを気にしていた。しかし、深刻なセキュリティインシデントが相次いで発生し、広範な影響を及ぼすようになると、この見方は変化した。ソフトウェアの購入者は、機能だけでなく、自分たちが使用している製品の内部に実際に何が存在しているのかを問い始めた。 SBOMはまさにそのタイミングで、直接的な答えとして登場した。SBOMは、ソフトウェアを構成するすべてのコンポーネントを詳細に一覧化し、これまで曖昧だったシステムを、検査、評価、追跡が可能な構造へと変える。 国際ソフトウェアの文脈におけるSBOMとは何か SBOM、すなわちSoftware Bill of Materialsは、簡単に言えばソフトウェアの原材料一覧と理解することができる。しかし、国際的な文脈において、SBOMは単なる技術文書ではない。それは、ベンダーと顧客、開発側と運用側、異なる法制度に属する組織同士をつなぐコミュニケーションの手段である。 標準的なSBOMは、ソフトウェアがどのコンポーネントを使用しているかを示すだけでなく、具体的なバージョン、出所、利用ライセンス、そしてコンポーネント間の依存関係も明らかにする。この詳細さこそが、SBOMをセキュリティ評価、法令遵守、さらにはソフトウェアの購買判断といった重要な活動の基盤にしている。 ソフトウェアが大規模かつ機密性の高いシステムに組み込まれることの多い国際環境において、SBOMは売り手と買い手の間の情報の非対称性を大きく減らす。包括的な約束を完全に信頼する代わりに、顧客はリスクを評価するための具体的なデータを手にすることができる。 なぜSBOMは国境を越えたソフトウェア取引の要件になりつつあるのか SBOMが技術的概念から商業的要件へと移行する動きは、静かではあるが非常に明確に進んでいる。国際的な企業の中で、特に契約締結前のデューデリジェンス段階において、ソフトウェアベンダー評価プロセスにSBOMを組み込むケースが増えている。 その理由は、ソフトウェアの連鎖的なリスクにある。企業がソフトウェアを購入する際、それは単に一つの製品を買うということではなく、そのソフトウェアが持つ依存関係の連鎖全体を自社システムに取り込むことを意味する。内部の一つのコンポーネントに深刻な脆弱性があれば、その影響は単一のアプリケーションの範囲をはるかに超えて広がる可能性がある。 SBOMは、購入者が意思決定を行う前に、その全体像を明確に把握することを可能にする。そのため、SBOMを要求することは不信の表れではなく、グローバルなビジネス環境における必要不可欠なリスク管理の一環である。特に金融、医療、デジタルインフラ分野の多くの組織にとって、SBOMのないソフトウェアを購入することは、測定不可能なリスクを受け入れることに等しい。 SBOMとソフトウェアベンダー評価の変化 これまで、ソフトウェアベンダーの能力は、経験、顧客リスト、技術要件への対応力によって評価されることが一般的だった。現在では、SBOMが新たな評価基準となりつつあり、製品ガバナンスにおける企業の成熟度を反映する指標となっている。 明確で最新のSBOMを持ち、国際標準に従っている企業は、自社のソフトウェアを深く理解し、サプライチェーンを管理し、長期的な責任を意識していることを示している。逆に、SBOMを提供できない、または表面的な文書しか提供できない場合、その企業は国際市場の厳しい要求にまだ対応できていないと見なされることが多い。 多くの場合、SBOMはベンダーを分類する要素となる。SBOMが充実している企業は、コストが最も低くなくても、選定プロセスにおいて優先されることが多い。これは、SBOMが支援的な役割から、国際競争における決定的な役割へと移行しつつあることを示している。 SBOMとソフトウェア契約における法的責任 SBOMが必須となりつつあるもう一つの重要な側面は、法的責任の問題である。ソフトウェアが大規模に導入されると、あらゆるセキュリティインシデントが契約紛争や訴訟に発展する可能性がある。 そのような状況において、SBOMは責任を特定するための根拠として機能する。脆弱性がサードパーティのコンポーネントに起因する場合、そのコンポーネントが申告されていたかどうか、契約上の約束の範囲に含まれていたかどうかをSBOMによって明確にできる。これは、アウトソーシング企業や受託開発ベンダーにとって特に重要であり、当事者間の責任範囲が不明確になりがちな領域である。 SBOMの存在は法的リスクを完全に排除するものではないが、企業が透明性を確保し、合理的なリスク管理プロセスを遵守していたことを示す助けとなる。ますます厳格化する国際的な法環境において、これは小さくない強みである。 SBOMは社内のソフトウェア開発プロセスにどのような影響を与えるのか SBOMは外部パートナーのためだけのものではなく、企業の内部におけるソフトウェア開発の在り方にも大きな変化をもたらす。SBOMが標準要件となることで、新しいライブラリやコンポーネントを使用する一つ一つの判断に、追加の責任が伴うようになる。 開発チームは、利便性や慣れだけでライブラリを選択することはできなくなり、出所、セキュリティ履歴、長期的な保守性を考慮する必要がある。時間の経過とともに、これはソフトウェアアーキテクチャの品質向上と技術的リスクの蓄積抑制につながる。 SBOMはまた、保守やアップグレードをより体系的にする。コンポーネントの置き換えや削除が必要な場合でも、企業は影響を評価するための全体像をすでに把握しており、ソースコードを手作業で探し回る必要がなくなる。 長期的な競争優位としてのSBOM SBOMの導入には、ツールやプロセスへの初期投資が必要であるが、長期的にはその価値はコストを大きく上回る。SBOMを備えた企業は、セキュリティインシデントへの対応が速く、停止時間を短縮し、評判の損失を抑えることができる。 さらに重要なのは、SBOMが国際的な顧客の目に専門的な企業イメージを築く助けとなる点である。透明性と安全性がますます重視される市場において、SBOMを提供できることは、単に要件を満たすだけでなく、品質と責任へのコミットメントを示す手段でもある。 結論 SBOMは、国際的なソフトウェア業界において、技術的概念から商業的かつ法的な標準へと移行しつつある。SBOMの有無は、ソフトウェアの販売、契約締結、市場拡大の可能性に直接的な影響を与えるようになっている。 ソフトウェアサプライチェーンがますます複雑化し、セキュリティリスクの予測が一層困難になる中で、SBOMはもはや選択肢ではない。ソフトウェアが持続可能な形でグローバル市場に進出するための必須条件となりつつある。この点に早く気づき、真剣に準備を進めた企業は、ソフトウェア産業の長期的な競争において明確な優位性を持つことになるだろう。 さらに読む:

クラウドネイティブ環境におけるゼロトラストアーキテクチャは、現代の企業におけるサイバーセキュリティ戦略の中核として、徐々に重要な位置を占めるようになっています。クラウドコンピューティング、コンテナ、マイクロサービスアーキテクチャの急速な発展により、情報システムの設計および運用方法は根本的に変化しました。そのような状況において、社内ネットワーク内は安全であるという前提に基づく従来のセキュリティモデルは、もはや適切ではありません。 ゼロトラストは、ネットワーク境界を防御するのではなく、リソースとデータの保護に重点を置く新しいアプローチとして登場しました。すべてのアクセスは潜在的なリスクを伴うものと見なされ、アクセス元に関係なく、継続的な検証が求められます。クラウドネイティブと組み合わさることで、ゼロトラストは単なるセキュリティツールの集合ではなく、クラウド上でのアプリケーションの設計、展開、運用と密接に結びついた包括的なアーキテクチャとなります。 クラウドネイティブの文脈におけるゼロトラストとは何か ゼロトラストは、デフォルトでは信頼せず、常に検証するという原則に基づくセキュリティモデルです。クラウドネイティブの文脈では、この原則はエンドユーザーだけでなく、サービス、コンテナ、自動化されたワークロードにも適用されます。 従来の環境とは異なり、クラウドネイティブ環境では、需要に応じてリソースが継続的に生成および削除されます。そのため、IPアドレス、サブネット、物理的な場所に依存したセキュリティメカニズムは効果が低下します。ゼロトラストは、これらの静的な要素を、アイデンティティ、コンテキスト、動的なポリシーに置き換えます。 米国国立標準技術研究所などの信頼性の高い参照フレームワークによると、クラウドネイティブにおけるゼロトラストは、個々のリソースを保護することを重視しています。すべてのアクセス要求は、認証、認可、記録のプロセスを経る必要があり、システムの一部が侵害された場合でもリスクを最小限に抑えることができます。 なぜクラウドネイティブにはゼロトラストが必要なのか クラウドネイティブは高い柔軟性と拡張性をもたらしますが、同時にセキュリティの複雑性も増大させます。最も大きな変化の一つは、明確なネットワーク境界が失われたことです。アプリケーションとデータは単一のデータセンターに存在するのではなく、複数のプラットフォームや地理的に分散した環境に配置されます。 さらに、クラウドネイティブ環境では変化のスピードが非常に速くなっています。コンテナやワークロードは短いライフサイクルを持ち、自動化されたパイプラインによって頻繁に再生成されます。このため、静的なアクセス制御リストを維持することは困難であり、誤りが生じやすくなります。 また、クラウドネイティブはAPI、サービスメッシュ、自動化ツールを通じて攻撃対象領域を大幅に拡大します。ゼロトラストは、強力な認証、詳細な権限管理、すべての接続に対する継続的な監視を要求することで、これらのリスクを制御するための適切なフレームワークを提供します。 クラウドネイティブなゼロトラストアーキテクチャの中核要素 アイデンティティを中心とした設計 アイデンティティは、クラウドネイティブなゼロトラストアーキテクチャにおいて基盤となる要素です。ユーザーだけでなく、アプリケーション、サービス、ワークロードも、それぞれ認証と認可のための固有のアイデンティティを持つ必要があります。集中型のアイデンティティ管理により、企業はアクセス権限をより効果的に制御し、従来のネットワーク要素への依存を減らすことができます。 多要素認証や、役割に基づく動的な権限付与メカニズムは、アクセス判断の信頼性を高めると同時に、セキュリティレベルを低下させることなくシステムの拡張を可能にします。 最小権限の原則 最小権限の原則は、ゼロトラストの重要な柱の一つです。クラウドネイティブ環境では、この原則は特定の役割やワークロードに紐づいた詳細なポリシーによって実装されます。 アクセス権限を制限することで、攻撃者が過剰な権限を悪用して影響範囲を拡大する可能性を低減できます。また、厳格な規制が求められる業界において、コンプライアンスや監査要件への対応も容易になります。 継続的な検証とコンテキスト評価 ゼロトラストでは、一度の認証ではなく、継続的な検証が求められます。すべてのアクセス要求は、デバイスの状態、位置情報、行動、現在のリスクレベルといったコンテキストに基づいて評価されます。 このアプローチにより、認証情報が漏洩した場合でも、新たに出現する脅威に対して柔軟に対応することが可能になります。 ワークロードと内部通信の保護 クラウドネイティブアーキテクチャでは、内部サービス間の通信がトラフィックの大部分を占めます。これらの通信フローを保護することは、ゼロトラストにおいて必須の要件です。 サービスメッシュや自動暗号化の仕組みにより、すべての接続が認証され、安全に保護されます。短期間有効な証明書の利用や自動ローテーションは、認証情報の不正利用リスクをさらに低減します。 クラウドネイティブにおけるゼロトラスト導入のメリット クラウドネイティブ環境にゼロトラストを導入することで、企業は多くの戦略的メリットを得ることができます。まず、内部攻撃やサプライチェーン攻撃を含む、ますます高度化する脅威に対する防御力が向上します。 また、インシデントが発生した場合でも、影響範囲を最小限に抑えることが可能です。厳格な権限管理と適切なセグメンテーションにより、攻撃者がシステム内を横断的に移動することは困難になります。 さらに、このアーキテクチャは、コンプライアンス対応やリスク管理の強化にも寄与します。何よりも、ゼロトラストは柔軟なセキュリティ基盤を提供し、安全性を損なうことなく、クラウドネイティブ環境における事業拡大とイノベーションを支援します。 クラウドネイティブにおける代表的なゼロトラスト導入モデル 実際には、ゼロトラストは単一の固定されたモデルで導入されるのではなく、各組織のセキュリティ成熟度やビジネス要件に応じて調整されます。 最も一般的な導入モデルは、アイデンティティとアクセス管理を中心としたゼロトラストです。このモデルでは、アイデンティティ管理システムがすべてのアクセス判断において中核的な役割を果たします。これは、クラウドネイティブへ移行したばかりの企業にとって、適切な出発点となります。 次のモデルは、アプリケーションおよびサービス層に焦点を当てたもので、マイクロサービス間の通信を相互認証と必須の暗号化によって保護します。このアプローチは、システム内部のリスクを低減し、可観測性を向上させます。 最も高度なモデルは、ユーザーからワークロードまでを包括的に統合したゼロトラストです。アクセス判断は、アイデンティティ、デバイスの状態、行動の組み合わせに基づいて行われます。このアプローチは、高度なセキュリティとコンプライアンスを求める組織に適しています。 結論 クラウドネイティブ環境におけるゼロトラストアーキテクチャは、単なるトレンドではなく、現代のサイバーセキュリティにおける必須要件となりつつあります。アイデンティティと継続的な検証を中心に据えることで、ゼロトラストは、分散され急速に変化するクラウド環境において、企業がリソースを効果的に保護することを可能にします。適切な導入は、持続可能なセキュリティ基盤を構築し、長期的な成長とイノベーションを支えることにつながります。 続きを読む:

長年にわたり、pandas は Python によるデータ分析エコシステムの中心的な存在であり続けてきました。ほぼすべてのデータサイエンス講座は pandas から始まり、多くの企業内分析システムもこのライブラリを基盤として構築されています。しかし、ビッグデータの急速な発展と、処理速度やスケーラビリティに対する要求の高まりにより、pandas はあらゆるシナリオにおいて最適な選択肢ではなくなりました。この状況が、より軽量で高速、かつ現代的なハードウェアに適した新しいライブラリの登場を後押ししています。 pandas の代替手段は、単に性能の問題を解決するだけでなく、データ処理に対する考え方の変化も反映しています。DataFrame を完全にメモリへ読み込む必要のある構造として捉えるのではなく、新しいツールは列指向処理、遅延クエリ、自動最適化を重視しています。これは現代的なデータ分析システムの基盤となる考え方です。 PANDAS の性能問題の概要 pandas は、分析対象データが主に中規模で、個人用マシン上で処理されることを前提とした時代背景の中で設計されました。pandas の内部アーキテクチャは NumPy に大きく依存しており、eager execution モデルを採用しています。これは、各操作が即座に実行され、多くの場合 DataFrame 全体を走査する必要があることを意味します。 データ量が数千万行、あるいは数億行規模に増加すると、pandas は次第に限界に直面します。処理の過程で中間コピーが生成されるため、メモリ消費は急激に増加します。また、pandas は主に単一の CPU スレッドで動作するため、マルチコアなどの現代的なハードウェア資源を十分に活用できません。 さらに、pandas は複雑な分析クエリに最適化されていないという問題もあります。groupby、join、複数条件による filter などの操作はコストが高く、手動での最適化も困難です。本番環境では、これが処理時間の長期化や予測困難な挙動につながる可能性があります。 こうした制約が、より柔軟なアーキテクチャと高い性能を備えた代替ソリューションを求める動きをコミュニティ内で加速させました。 POLARS: 高性能 DATAFRAME の潮流 Polars は、性能を最優先に設計された新世代 DataFrame ライブラリの代表例です。Rust を採用することで、安全なメモリ管理と高い処理速度を最大限に活用しています。pandas とは異なり、Polars は最初からマルチスレッド処理と CPU 全体の活用を前提として設計されています。 重要な違いの一つとして、Polars は lazy execution モデルを採用しています。ユーザーはデータ変換の一連の処理を、即座に実行することなく構築できます。Polars はパイプライン全体を解析し、最適な実行計画を生成します。これにより、不要な操作を排除し、データ走査回数を減らし、実行順序を最適化できます。 また、Polars は Apache Arrow 標準に基づく列指向データ処理を行います。これにより処理速度が向上するだけでなく、メモリ使用量も大幅に削減されます。実際のベンチマークでは、同じデータセットに対して Polars が pandas より何倍も高速に処理するケースが多く見られます。 Polars は、多数の複雑な変換を繰り返す必要がある大規模データ分析プロジェクトに特に適しています。ただし、pandas から Polars へ移行するには、新しい API とパイプライン指向のデータ処理思想に慣れる必要があります。 DUCKDB: SQL によるデータ分析の台頭 DuckDB は pandas や Polars とはまったく異なるアプローチを提供します。純粋な Python DataFrame API を提供する代わりに、高性能な組み込み型分析 SQL エンジンを中心に設計されています。これにより、データをメモリに読み込むことなく、ファイル上のデータに対して直接 SQL クエリを実行できます。 DuckDB の大きな利点は、自動クエリ最適化機能です。ユーザーはデータの保存方法やアクセス方法を意識する必要がありません。DuckDB が自動的に最も効率的な実行戦略を選択します。これは、SQL に慣れ親しんだデータアナリストが、複雑なデータ処理コードを書くことを避けたい場合に特に有効です。 DuckDB は Parquet や Arrow などの現代的なデータ形式も強力にサポートしています。そのため、既存のデータパイプラインへの統合も容易です。多くのケースにおいて、DuckDB は探索的分析や集計タスクにおいて pandas を完全に置き換えることができます。 ただし、DuckDB はすべての用途に適しているわけではありません。行単位の処理が必要なタスクや、Python の機械学習ライブラリと深く統合する場合には、従来型の DataFrame の方が便利なこともあります。 PYARROW: 現代的な列指向データ基盤 PyArrow は、高性能データ分析ツール群の基盤レイヤーとしての役割を担っています。Apache Arrow は、言語間でデータをコピーせずに共有できる、インメモリ列指向データ形式を定義しています。これは、システム間でのデータ変換コストという pandas の大きな課題を解決します。 Parquet や Feather などの列指向フォーマットを PyArrow で読み書きする場合、その速度は pandas を上回ることが多くあります。これは、入出力処理が全体の処理時間の大部分を占めるデータパイプラインにおいて特に重要です。 PyArrow は、エンドユーザー向け API のレベルで pandas を置き換えることを目的としていません。その代わりに、より強力な分析ツールを構築するための基盤を提供します。Polars や DuckDB など多くの新しいライブラリが Arrow を基盤としていることは、PyArrow がデータエコシステムにおいて戦略的に重要な存在であることを示しています。 データエンジニアにとって、PyArrow は高性能かつスケーラブルなデータパイプラインを構築する際に欠かせないコンポーネントです。 MODIN: 使い慣れた PANDAS を拡張するアプローチ Modin は、pandas から並列処理への移行に伴う障壁を下げることを目的として設計されています。このライブラリは pandas の API をそのまま維持しつつ、複数の CPU コア、あるいはクラスタ全体に処理を分散します。これにより、コードのロジックを変更することなく処理速度を向上させることが可能です。 Modin のアプローチは、pandas のコードベースに多大な投資をしてきた組織にとって特に魅力的です。Polars のようなまったく新しいライブラリへ移行するには、時間と教育コストがかかります。Modin は、使い慣れた操作感を維持しながら性能を改善する中間的な解決策を提供します。 しかし、Modin が常に大きな性能向上をもたらすわけではありません。小規模なデータセットや単純な操作では、並列管理のオーバーヘッドによって効率が低下することもあります。また、Modin を用いたデバッグや性能最適化は、純粋な pandas よりも複雑になる場合があります。 Modin は、既存のワークフローを中断することなく、段階的にシステムを拡張する必要がある企業環境に最も適しています。 DASK: メモリを超えるデータ処理 Dask は、pandas では効率的に処理できない問題、すなわち RAM を超えるサイズのデータを扱うために設計されています。データ全体をメモリに読み込む代わりに、Dask はデータを小さなチャンクに分割し、lazy execution モデルで処理します。最終結果が要求された時点でのみ計算が実行されます。 このアプローチにより、Dask は個人用マシンや分散クラスタ上で非常に大規模なデータセットを処理できます。Dask は NumPy、pandas、scikit learn などを含む Python エコシステムとも良好に統合されています。 一方で、Dask を使うには、パイプラインの構築方法や、実際に計算が行われるタイミングをより深く理解する必要があります。Dask の性能を最適化するには、分散データ処理に関する経験と知識が求められます。 Dask は、入力データが従来の pandas では扱えない規模の、大規模データサイエンスや機械学習プロジェクトに特に適しています。 PANDAS の代わりにどの解決策を選ぶべきか pandas の代替を選択する際は、流行ではなくプロジェクトの実際の要件に基づくべきです。小規模から中規模のデータであれば、pandas は依然として効果的で使いやすいツールです。しかし、データ量が増加したり、性能要件が厳しくなった場合には、他のソリューションが強みを発揮します。 Polars は高速処理とメモリ効率が求められる場合に適しています。DuckDB は SQL ベースの分析やファイル形式データに理想的な選択肢です。PyArrow は現代的なデータパイプラインの基盤として機能します。Modin は既存の pandas コードを大きく変更せずに拡張できます。Dask は RAM を超える大規模データの問題を解決します。 多くの実運用システムでは、複数のツールを組み合わせることが一般的です。例えば、DuckDB を初期データのクエリに使用し、Polars でより深い処理と変換を行い、最終的な分析には pandas を使うといった構成が考えられます。 結論 pandas の代替ライブラリの登場は、Python データ分析エコシステムが成熟段階に入ったことを示しています。あらゆる状況に適した単一のツールはもはや存在せず、代わりに、課題ごとに特化したソリューションの集合体となっています。 各ライブラリの長所と短所を正しく理解することで、データ専門家はより適切な判断を下し、より効率的な分析システムを構築できます。すべてのプロジェクトで pandas をデフォルトの選択肢とみなすのではなく、代替手段を真剣に評価することが、性能、スケーラビリティ、そしてシステムの持続可能性において長期的な価値をもたらします。 さらに読む:

技術測定モデルの選択はソフトウェア開発組織にとって戦略的な決定になりつつある。多くの企業は導入を加速するためにDORAを採用しているがチームのパフォーマンスが持続的に改善されないことに気付いている。いくつかの企業は人間的要素を補うためにSPACEに切り替えるが主観的なデータのために実施が難しいと感じている。別のグループはエンジニアの体験を改善することを期待してDevExを優先するがビジネス目標に結び付く具体的な運用指標が不足している。このことは技術チームが答えるべき中心的な問いつまりどのモデルが本当に適しているのかそしてどの状況で適しているのかという点につながる。 DORA SPACE DevExの違いはデータの収集方法だけでなくエンジニアの生産性に対する哲学にもある。DORAは速度と安定性を優先する。SPACEは生産性の全体像を反映しようとする。DevExはエンジニアの実際の経験に深く踏み込む。各モデルは異なる側面を扱っており誤った選択は運用方法に歪みをもたらす。本稿では各モデルの強み弱みそして適した文脈を明確に分析し流行に流されずに正しい選択ができるようにする。 測定システムの需要が高まっている理由 現代の技術エコシステムの複雑性は組織に対して多次元で進捗と品質を制御する能力を求めている。製品がより速く進化し展開サイクルが短くなり変更要求が絶えず増えチームの規模が複雑化すると管理者の直感だけでは評価ができなくなる。そのため専門的な測定モデルの必要性が高まっている。 さらに技術運用におけるデータ利用は一般的な標準となっている。企業は推測ではなく実際の証拠に基づいて意思決定を行いたいと望んでいる。このことが開発チームの働き方を多角的に反映する多くの測定フレームワークの登場を促している。 DORAの概要 速度と安定性に注目する視点 DORAはGoogleの研究に基づいて構築され急速に業界標準となった。DORAは高い安定性と速度でソフトウェアを本番環境に届ける開発チームの能力に焦点を当てている。DORAの四つの主要指標は展開頻度変更リードタイム復旧時間そして展開失敗率である。 DORAは明確であり運用品質に直接影響を与えられるという大きな利点を持つ。これら四つの指標を改善できれば組織は製品の移行速度と信頼性をほぼ確実に向上させることができる。 しかしDORAは技術プロセスの成果物に主に着目しており人間的要素を十分に反映していないという指摘もある。あるチームは高いDORAスコアを達成していても燃え尽き内部対立劣悪な職務体験といった問題を抱えることがある。この指摘がSPACEやDevExなどの補完モデルの誕生につながった。 SPACEはエンジニアの生産性を包括的に捉えることを目指す SPACEはGitHub Microsoft ビクトリア大学の研究チームによって開発され出力だけに基づくのではなく多次元でエンジニアの生産性を評価する方法を示す。モデル名は満足度パフォーマンス活動レベルコミュニケーションプロセスの有効性の五つの要素から構成される。 SPACEの最大の強みはエンジニアの生産性の複雑性を認識している点である。このモデルは心理的要素と職場環境を重視しておりこれらが持続的な成果の基盤であるとする。コミット数や展開回数が必ずしも人間の能力を正しく反映するとは限らないため個人の満足度やコミュニケーションの質を加えることで評価の偏りを抑えることができる。 一方でSPACEの測定には多くの定性的データが必要となる。内部調査はエンジニアの主観的な感覚を収集する唯一の方法であり組織文化の影響を受けやすい。透明性に慣れていないチームは正直に回答しない可能性がありデータが歪む。 DEVEXは開発者体験に焦点を当てる DevExすなわち開発者体験はMicrosoft GitHubおよび多くの大規模組織の最新研究から生まれた。このモデルはソフトウェア開発の効果がエンジニアが日々経験する体験に深く依存するとしている。良い体験はエンジニアが集中し創造性を発揮し技術的障害の悪影響を抑える助けとなる。 DevExは満足度技術環境からのサポートワークフローの維持能力の三つの要素に注目する。肯定的な体験は気が散る要素の削減一貫したプロセス明確なドキュメント信頼できるツールと密接に関連する。 DevExの限界は直接的な運用成果をあまり重視しない点である。DevExが優れていてもDORAのような指標と組み合わせない限り展開速度が速いまたは高い安定性を持つとは限らない。 三つのモデルを比較し各システムの価値を把握する DORA SPACE DevExはいずれもソフトウェア開発の効果を評価することを目的としているが重視する点は大きく異なる。三つの指標群を比較することで組織は相互補完の関係を理解できる。 DORAは移行速度とシステム安定性に強く焦点を当てる。これは高負荷のプロダクトを持つ大企業など運用効率を重視する環境に適している。 SPACEは人間的要素を評価システムに取り入れることでより包括的である。実際の生産性と測定される生産性のギャップを縮めたい組織に適している。 DevExはエンジニアの日常体験に深く踏み込み拡大期の企業やプロセス上の障害が多い組織においてワークフローのボトルネックを特定する助けとなる。 DORAを主要モデルとして選ぶべきとき 市場投入速度を改善したいまたは展開品質に問題を抱えている場合DORAが適している。DORAは技術プロセスのボトルネックを非常に明確に示す。 また企業が最新アーキテクチャへの移行期や継続的デリバリー文化を導入している段階にも適している。DORAのデータは各フェーズの進捗を測定するために役立つ。 しかしチームがプレッシャーや文化的問題を抱えている場合DORAに偏りすぎると監視されていると感じさせてしまう。したがって慎重に使用し他の指標と組み合わせてバランスを取るべきである。 SPACEを優先すべきとき SPACEは人を中心に置く組織に適している。エンジニアが過負荷を感じたり孤立したり対立が増えている場合このモデルは根本原因を発見する助けとなる。 成長期にあるスタートアップはSPACEを特に必要とする。開発チームが拡大するとコミュニケーション維持やプロセス最適化が大きな課題となる。SPACEは技術出力だけでは見えない生産性の全体像を提供する。 ただしSPACEは主観性と切り離せないため内部調査を科学的に実施しデータの信頼性を確保する必要がある。 DEVEXが最適となるとき DevExはエンジニアの体験を向上させスムーズに働けるようにしたい組織に適している。ツールが不安定プロセスが不一致ドキュメントが分かりにくいという状況ではDevExが改善の鍵となる。 中断による隠れたコストを削減したい企業にも非常に効果的である。エンジニアが環境エラーの解決や混乱したドキュメントの検索に二時間を費やすことは大きな浪費である。DevExはこのような問題を発見し削減する助けとなる。 しかし運用結果を追跡せずにDevExだけに集中すると体験を過度に最適化する一方でビジネス目標を達成できない可能性がある。 DORA SPACE DEVEXを組み合わせるべきか 多くの専門家は三つのモデルを組み合わせることを推奨している。DORAは運用結果を客観的に評価する。SPACEはチームの健全性を理解する助けとなる。DevExは日常的な作業環境への洞察を与える。 三つのモデルを組み合わせることで多次元な測定システムを構築できる。例えば展開指標が改善してもエンジニアの満足度が大きく低下した場合それはプレッシャーが増しているというサインである。これは長期的な悪影響を避けるために早期対応が必要となる。 三つのモデルから包括的な測定システムを構築する方法 三つのモデルを効果的に利用するために組織は基本原則に従う必要がある。 * 第一歩 ビジネス目標を明確にする。安定性の向上が目的ならDORAが中心になる。組織文化を改善したい場合はSPACEまたはDevExを優先する。 * 第二歩 チームごとに適切な指標を選ぶ。すべての部門が全ての指標を必要とするわけではない。運用チームはDORAをより多く使い内部プラットフォームチームはDevExを重視することがある。 * 第三歩 透明性のあるデータ収集プロセスを設計する。定性的指標には明確なアンケートが必要であり匿名性を保証しなければならない。運用データにはソースコード管理システムやCIプラットフォームとの統合が必要となる。 * 第四歩 継続的なコミュニケーションを実施する。指標はその意味を皆が理解して初めて価値を持つ。エンジニアが測定の利点を理解できるよう内部共有会を行うべきである。 結論 DORA SPACE DevExは互いに補完し合う測定モデルである。DORAは展開品質を管理しSPACEは生産性の全体像を示しDevExはエンジニアの実体験に焦点を当てる。どのモデルも絶対的な選択肢ではない。重要なのは各システムの本質を理解し組織のニーズに合わせて組み合わせることである。 効果的な測定戦略は持続可能なソフトウェア開発のための強固な基盤を築きチームが精神的健康や製品品質を犠牲にすることなく高い生産性を維持できるようにする。 さらに読む:
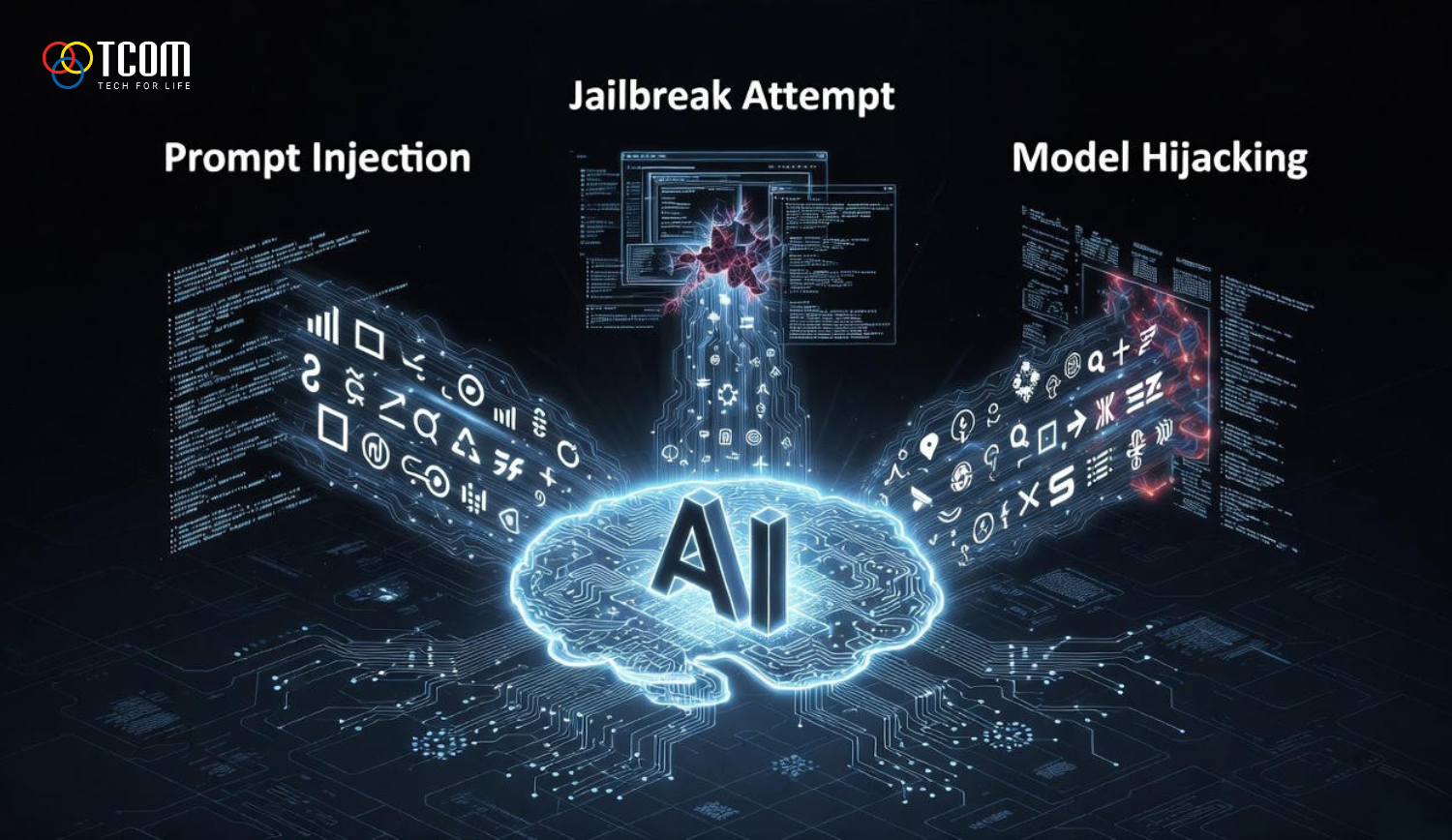
生成AI特に大規模言語モデルの急速な発展によりこれらは顧客対応チャットボット文書分析システム個人アシスタントから企業の自動化タスクまであらゆる製品に統合されている。モデルが言語理解能力と知的な行動能力を高めるにつれ攻撃面も同時に拡大している。多くの組織は十分な防御層を構築する前にLLMを急いで導入してしまいその結果モデルがインフラの弱点となる危険性を生んでいる。 この文脈においてセキュリティ専門家が最も頻繁に言及する三つの主要な攻撃手法がある。それがプロンプトインジェクションジェイルブレイクそしてモデルハイジャックである。これらの技術は理論上のものではなく主要なセキュリティ会議の実験や商用製品のインシデントによって実際に確認されている。それらが危険なのは攻撃者が低レベルの知識を必要とせずモデルの言語処理の仕組みそのものを悪用できる点にある。 本記事では各攻撃手法の特徴実際に起こり得る状況そして組織が多層的戦略によってリスクを最小限に抑える方法について包括的に紹介する。 プロンプトインジェクションとは何かその仕組み プロンプトインジェクションは言語モデルの根幹的な動作メカニズムを狙った攻撃である。AIにリクエストを送るとシステムは内部指示とユーザーが提供したデータを組み合わせて回答を生成する。攻撃者はこの混合プロセスそのものを悪用する。 攻撃者は通常の文書に見せかけた命令文をコンテキスト内に紛れ込ませる。例えばメモメール製品説明文の一部などである。モデルがその情報を処理するとそれを実行すべき指示と誤認してしまう可能性がある。その結果モデルは意図しない行動を取り機密情報の漏洩業務プロセスの改ざんあるいは実行すべきでない処理を行うなどの危険につながる。 プロンプトインジェクションの厄介な点はユーザーが意図していなくても発生し得ることである。例えばアップロードされたファイルに隠された命令文が含まれている場合や外部リンク先の悪意ある内容が自動的にコンテキストに取り込まれるケースなどがある。セキュリティ会議のデモでは単純なカレンダーイベントや巧妙に埋め込まれたテキストを含む文書がシステムに意図しない動作をさせる例が複数示されている。 ジェイルブレイクとは何かプロンプトインジェクションとの違い ジェイルブレイクはプロンプトインジェクションの一種だが目的が明確でモデルが開発者によって設定された安全規則を無視するよう強制する点が異なる。プロンプトインジェクションが任意の行動を誘導するのに対しジェイルブレイクはモデルの防御層に直接攻撃を仕掛ける。 商用モデルの多くには危険な内容や機密情報の提供を防ぐための規則が設定されている。しかし攻撃者は物語の語り手役割演技シナリオ設定などを利用しモデルに安全ルールが適用されないと誤認させる表現を作り出す。例えば禁止情報の提供が物語の文脈上正当化される状況にモデルを誘導することである。 ジェイルブレイクが高度なのはモデルが文脈の論理性を優先する傾向や推論の仕組みを利用する点である。研究では強化された安全機構を持つモデルであっても複雑な役割設定多段階の指示を用いることで破られる可能性があることが示されている。 モデルハイジャックとは何かどのような危険があるのか プロンプトインジェクションとジェイルブレイクが利用段階で発生するのに対しモデルハイジャックは学習または微調整工程に関連する。 モデルハイジャックは攻撃者が学習データ内に意図的に不正なサンプルを混入させることで発生する。モデルはそれらのサンプルから学習しバックドアと呼ばれる隠れた動作を獲得する。通常の条件では正常に動作するが特定のトリガーが与えられると攻撃者が設計した不正動作を実行する。例えば誤った情報を返す機密データを外部に送るなどである。 このリスクはオープンソースモデルや第三者から提供されたデータを用いた学習で特に高い。低コストのファインチューニングが広がる中小規模企業では検証が不十分なデータを用いてしまうリスクがある。研究では無害なタスクに見える文書分類モデルの微調整中にバックドアが埋め込まれた事例が報告されている。 実際の影響と注意すべきリスク これら三種類の攻撃は単に誤った回答を返すだけではなくAIが外部システムと連携している場合に深刻な実害を引き起こす。 攻撃により顧客情報内部ソースコード機密文書などのデータ漏洩が発生する可能性がある。文書要約や社内コンテンツ処理にAIを用いる企業にとってこれは特に重大な問題である。 さらに不正操作されたモデルが有害なコンテンツを生成すると企業の評判や法的リスクにも直結する。規制違反につながる指示を出す可能性もある。 また研究ではプロンプトインジェクションによってIoTやAIアシスタントが誤作動しデバイス操作や自動通知送信が行われる例も示されている。ソフトウェア攻撃と物理世界の攻撃の境界が曖昧になりつつあることを示している。 検知の原則と警戒すべき兆候 不自然な要求が現れた場合システムが攻撃を受けている可能性がある。例えば指示の無視を要求する内部データの提供を求める用途外の行動変更を促すなどである。 入力に全ての指示を無視してほしい極秘情報を提供せよなどの表現や不自然な符号化文字列が含まれていれば警戒すべきである。 さらにモデルの返答が業務プロセスと一致しない場合も危険信号である。例えばAIが敏感な行動を提案したり重要データを含むメールを自動送信したり業務範囲を逸脱した内容を生成するケースである。 実際には内容フィルタリング行動分析一貫性チェック独立モデルによる出力評価など複数技術を組み合わせることで検知精度が高まる。 リスクを減らすための多層防御策 AIシステムをプロンプトインジェクションジェイルブレイクモデルハイジャックから守るには多層防御の考え方が重要である。細かい対策を広く並べるより柱となるポイントを深く確実に実施する方が効果的である。 モデル入力データの厳格な管理 攻撃の多くは信頼できないデータから始まるため最重要の防御層はユーザーデータとモデル指示を明確に分離することである。アップロードファイル外部サイト内容未検証テキストなどをそのままプロンプトに混在させるべきではない。外部データは安全でない前提で扱い隠れた指示や撹乱的文字列の検査を通す必要がある。 AIの行動権限を制限し認証層を追加する 仮にモデルが騙されて行動を変えても敏感な操作権限がなければ被害は発生しない。企業はAIがAPIを呼び出すデータ送信設定変更を行う前に独立した認証を設ける必要がある。リスクのある行動は必ずユーザー確認を求め全操作をログ化しインシデント分析に備えるべきである。 出力の利用前の評価とフィルタリング 処理の最終段階に検閲層を設置することでプロンプトインジェクションとジェイルブレイクの影響を大幅に軽減できる。この層は第二モデルルールセットリスク分析システムなどで構成できる。これによりモデルが誘導されてしまった場合でもポリシー外の内容を検出できる。 学習工程の保護によるモデルハイジャック対策 内部モデルまたは微調整モデルの場合学習データの厳格な検証手順が必要である。データは信頼できる由来を持ち重要サンプルは手動確認するべきである。学習後はモデルの異常動作トリガー反応がないかを評価しバックドア混入をチェックする。 継続的な監視とインシデント対応 AIの動作をリアルタイムで監視し異常変化があれば敏感操作を一時停止し警告を発する必要がある。詳細ログは原因分析と今後の防御強化の重要な資産となる。 開発者とセキュリティチームのためのクイックチェックリスト * 信頼データと不信頼データを常に分離する。 * 入力フィルタリングで隠れた命令文の検出を行う。 * 敏感操作には多段階認証を導入する。 * 補助モデルまたはルールによる出力検閲を行う。 * 学習および微調整データを厳密に審査する。 * 包括的なログ記録と異常検知アラートを設定する。 実装例 社内文書検索用チャットボットを構築する場合ユーザーの質問部分と添付データをまず分離する必要がある。添付データは隠れた指示を含む可能性があるため検査に通し異常があれば審査キューへ送る。 AIが機密データを使って回答する場合システムは表示前にユーザー確認を要求する。AIがメール送信やシステム操作などのアクション要求を生成した場合は独立認証層を通す必要がある。この方法によりモデルがプロンプトインジェクションを受けても危険な操作が自動的に行われることを防ぐ。 結論 プロンプトインジェクションジェイルブレイクモデルハイジャックは現代AIセキュリティにおける最大の課題である。これらの攻撃はモデルの言語理解と実行特性という本質的弱点を突くため完全に排除することは難しい。しかし多層防御データ源管理行動認証継続監視出力検閲を組み合わせることで企業はリスクを許容レベルまで下げることができる。 AIセキュリティは一度きりの作業ではなく継続的なプロセスである。モデルが高度化し統合が進むほどAIセキュリティへの投資はすべての現代企業にとって必須となる。 さらに読む:

現代のソフトウェア開発の文脈において、製品の市場投入までの時間はますます短くなり、品質への期待は高まり、継続的な変更が求められています。その要求に応えるため、DevOpsに基づく開発手法は標準となっています。しかし、DevOpsは単に開発チームと運用チームを統合するだけでなく、全体のプロセスにわたって効果的なテスト戦略を必要とします。Continuous Testing、すなわち継続的テストはその解決策です。 Continuous Testingは、テストを開発サイクルの最後の段階から継続的なプロセスに変え、DevOpsのパイプラインに組み込みます。テストがプロセスの不可欠な部分になると、ソフトウェアの品質は積極的に保証され、バグは早期に検出され、製品は常にリリース可能な状態となります。 以下の記事では、なぜContinuous Testingが重要であるか、どのように導入するか、利点、課題、そして持続可能なDevOpsパイプラインを構築するためのベストプラクティスについて詳しく解説します。 1. CONTINUOUS TESTINGとは何か Continuous Testingは、ソフトウェアのテストを自動化し、継続的かつ繰り返し実行するプロセスであり、ソースコードや設定に変更があるたびに行われます。DevOpsの文脈では、Continuous Testingは通常、継続的インテグレーションおよび継続的デプロイメントのパイプラインに統合されます。新しいコミットがソースコードリポジトリにプッシュされると、システムは自動的にユニットテスト、統合テスト、APIテスト、エンドツーエンドの機能テスト、さらにはパフォーマンスおよびセキュリティテストを実行して即座に品質を評価します。バグが検出された場合、パイプラインは停止します。テストをクリアすれば、コードは次の段階に進み、製品のデプロイに至ることも可能です。 このように、Continuous Testingは単なるテストの自動化ではなく、品質を開発の各ステップに組み込む戦略であり、チーム全体の共通の利益として品質を確立します。 2. DEVOPSにおけるCONTINUOUS TESTINGの重要性 2.1. 早期のバグ発見と修正コストの削減 Continuous Testingの重要な原則は、早期かつ頻繁なテストです。コードの変更直後にテストが実行されることで、問題が複雑化する前にバグを即座に発見できます。早期発見により修正コストは大幅に削減され、後で検出された場合やリリース後の修正と比べて簡単に対処できます。 Continuous Testingは、テストの自動化、バグの早期発見、ソフトウェア品質の向上を支援します 2.2. 安定的かつ包括的なソフトウェア品質の保証 Continuous Testingは通常、複数のテストタイプを組み合わせてソフトウェアを多角的に評価します。これにより、各変更が他の部分を壊さず、再発バグを生まず、品質基準を維持できます。継続的にテストを実施することで、ソフトウェアの安定性と信頼性が持続的に維持されます。 2.3. リリース速度の向上と市場投入時間の短縮 自動化テストがパイプラインに密接に組み込まれることで、ビルド、テスト、デプロイの各ステップは手動テストや独立したQAフェーズを待たずに継続的に実行できます。その結果、コード作成からテスト環境や本番環境への展開までの時間が大幅に短縮されます。Continuous Testingを組み込んだDevOpsパイプラインは、リリースを迅速かつ定期的に行いながら品質を保証することが可能であり、迅速かつ柔軟な開発環境では特に重要です。 2.4. 品質文化の構築と協力の促進 テストがQAの専任業務ではなくチーム全体の責任になると、すべてのメンバーが品質に対する共通認識を持ち、コードの安定動作や安全なデプロイに責任を持つようになります。Continuous Testingはパイプラインの透明性を高めます。すべてのコミット、ビルド、テストが追跡可能となり、コードが良好かどうかが全員に分かります。透明性と共通責任によりコミュニケーションが改善され、部門間の障壁が減り、DevOpsはツールと開発文化の両面でより包括的な実践となります。 3. CONTINUOUS TESTINGをDEVOPSパイプラインに統合する方法 Continuous Testingの導入は単に自動化を有効にすることではなく、プロセス、ツール、働き方の文化を組み合わせた総合戦略が必要です。まず、テストスイートは多層をカバーするように設計する必要があります。ユニットテストは小さなロジックを評価し、統合テストやAPIテストはモジュール間の同期を確認し、エンドツーエンドの機能テストは実際のユーザーフローをシミュレーションします。さらに、プロジェクトの要件に応じてパフォーマンスおよびセキュリティテストも考慮する必要があります。可能な限り自動化を優先すべきです。手動テストではDevOpsのスピードに対応できず、自動化により時間を節約し、人為的ミスを減らし、定期的なテストを確実に行えます。 パイプラインには継続的テストを組み込み、新しいコミットがあるたびに全テストが自動で実行されるようにします。テストに失敗した場合、パイプラインは停止し、コードは統合やデプロイされません。テストをクリアすれば、コードはテスト環境や製品デプロイに進むことができます。同時に、コードカバレッジ、機能テスト結果、パフォーマンス、セキュリティなどの品質ゲートとフィードバックループを設定します。テスト失敗時には即座に開発者にフィードバックを送信し、バグを迅速に修正してパイプラインを継続的に効率よく稼働させます。 もう一つ重要な要素はテスト環境です。この環境は本番環境にできるだけ近い構成、データ、依存関係をシミュレーションすべきです。これにより、テストと本番環境の乖離を減らし、テストでは問題がなくても実際の展開でエラーが発生する状況を避けられます。さらに、スマートなテスト戦略の適用も必要です。アプリケーションのすべての部分が同じ重要度を持つわけではないため、データ、トランザクション、セキュリティに敏感なモジュールはより頻繁かつ徹底的にテストすべきです。この戦略により、テストリソースを最適化し、最も価値の高い部分に集中できます。 4. CONTINUOUS TESTINGの導入における課題 Continuous Testingは多くの戦略的および実践的利点を提供しますが、DevOps環境での導入と維持は必ずしも容易ではありません。組織は潜在的な課題を認識し、適切な対策を準備する必要があります。 テスト環境の課題、大量のテスト、バグ対応のプレッシャー 4.1. 初期コストと労力 最大の課題の一つは初期コストと労力です。Continuous Testingを導入するには、自動テストの構築、継続的インテグレーションおよびデプロイメントパイプラインの設定、安定したテスト環境の作成、インフラの維持に投資する必要があります。 エンドツーエンドの機能テストやパフォーマンステストを含む自動テストスイートの作成は、高度な技術と多くの時間を要します。経験豊富なQAチームや自動化エンジニアがいない場合、導入は困難となります。大規模プロジェクトや複雑なアプリケーションでは初期の人件費と技術費用が大きくなる可能性があります。 さらに、新しいツールやプロセスに慣れるための教育も課題です。開発者やQAチームが自動テストに不慣れな場合、テスト作成、テストスイートの維持、パイプラインで発生するバグ対応に苦労するでしょう。 4.2. 大規模テストスイートと長時間実行 プロジェクト全体で継続的にテストを実施すると、実行するテストの数は非常に多くなる可能性があります。特に統合テストやエンドツーエンドの機能テストは時間を要します。 最適化されていない場合、パイプラインが遅くなり、開発およびデプロイのリズムが妨げられます。場合によっては、開発者がコミットやマージを続ける前にテスト結果を長時間待たなければならず、生産性やモチベーションに影響し、自動テストの無視や中断につながることもあります。 この問題に対処するため、組織はテストを優先度で分類し、各コミットで最速のテストを実行し、重いテストは定期的または本番展開前に実行する必要があります。スピードとテストカバレッジのバランスを取ることは重要な技術的課題です。 4.3. 安定したテスト環境と本番環境の再現 もう一つの課題は、安定して本番環境に近いテスト環境を作成し維持することです。テスト環境が本番環境と大きく異なる場合、テスト結果は製品の品質を正確に反映しない可能性があります。 完全なテスト環境には、データベース、システム設定、サンプルデータ、ソフトウェア依存関係を含める必要があります。この環境を複数のブランチやモジュールが存在する場合に安定して維持することは大きな課題です。 さらに、テスト環境と本番環境のデータ同期は、セキュリティやユーザーのプライバシー、システムパフォーマンスに影響を与えないようにする必要があります。これにはインフラ、データベース、セキュリティに関する高度な知識が必要であり、組織にリソースの負荷をかけます。 4.4. 組織文化とマインドセット Continuous Testingは、開発チーム全体の文化とマインドセットの変化を要求します。すべてのチームが自動テストや継続的テストに慣れているわけではありません。開発者、QA、運用が旧来のサイクル終盤でのテストを主に行っている場合、Continuous Testingは効果を発揮しにくくなります。 成功するためには、チーム全体が品質を共通の責任と理解し、テストを開発プロセスの不可欠な部分と認識する必要があります。これには、透明性、責任共有、部門横断的協力を推進するリーダーシップが必要です。マインドセットの変革は長期的なプロセスであり、経営陣と技術チームのコミットメントが不可欠です。 4.5. テストの保守と拡張の困難 ソフトウェアシステムが進化するにつれ、自動テストスイートも継続的に維持・更新する必要があります。機能、モジュール、アーキテクチャの変更により、既存のテストが古くなったり不適切になることがあります。 大規模テストスイートの維持、テストシナリオの更新、不要なテストの削除は継続的な作業です。適切に管理されないと、テストスイートが重くなり、保守が困難になり、パイプラインが遅くなります。これは多くの組織がContinuous Testing導入時に見落としがちな重要な技術および管理上の課題です。 4.6. ツールコストと管理 Continuous Testingは、テスト管理、テスト実行、結果レポート、パイプライン支援インフラなど、多くの自動化ツールの使用を必要とします。適切なツールの選定、ツール間の統合、安定稼働の維持も課題です。 さらに、ソフトウェアライセンス費用、サーバーインフラ費用、テストデータ保存コストも考慮する必要があります。十分に計算しないと、費用が予算を超過したり、費用対効果が得られない可能性があります。 4.7. テストデータの管理 Continuous Testingは、テスト結果、エラーログ、パフォーマンスレポートなど大量のデータを生成します。これらのデータを効果的に管理、保存、分析、活用して開発プロセスを改善することは容易ではありません。 組織は、データの価値を引き出すために、可視化レポート、ダッシュボード、エラー傾向分析のシステムを構築する必要があります。これを行わないと、データは余剰情報となり、リソースを消費するだけで実質的な利益をもたらしません。 5. CONTINUOUS TESTINGを適用すべき状況 Continuous Testingは、開発が迅速で変更が多く、頻繁にリリースが必要で、高い品質が求められ、DevOps文化と十分なリソースがあるプロジェクトに適しています。リスクを減らし、保守コストを削減し、製品の信頼性を向上させます。 5.1. 開発速度が速く変更が多いプロジェクト Continuous Testingは、開発が迅速で頻繁に変更され、継続的リリースが求められるプロジェクトに特に適しています。アジャイル環境やサービス製品開発企業では、機能が継続的に更新され、リリースは迅速に行われます。 Continuous Testingがなければ、コード変更によるバグの蓄積、モジュール間の衝突、他の機能への影響が発生する可能性があります。Continuous Testingにより、コード変更時に即座にバグが検出され、リスクを軽減し、製品の安定性を確保できます。 5.2. 高品質で安定したソフトウェアが求められるプロジェクト 特に金融、医療、Eコマース、重要制御システムなどの重要なアプリケーションは、高品質、安定性、継続稼働能力が求められます。 Continuous Testingにより、コード変更は機能、セキュリティ、パフォーマンスの複数の観点でテストされます。これにより、本番環境で重大なバグが発生するリスクが減少し、製品の信頼性が向上します。ソフトウェアバグが経済的損失やブランド信頼の低下につながる場合、特に重要です。 5.3. 十分なスキルとリソースを持つチーム Continuous Testingの導入には、プログラミング、自動化テスト、DevOpsの経験を持つチームが必要です。十分なスキルを持つエンジニアがいない場合、導入は困難で効果が出にくくなります。 チームは、自動テスト作成、パイプライン管理、テスト環境の維持、テスト結果データの処理ができる必要があります。同時に、DevOpsプロセスと共通責任のマインドセットに適応するための教育も重要です。 5.4. リスクと保守コストを削減したいプロジェクト Continuous Testingは、ソフトウェアバグによるリスクや修正コストが高いプロジェクトに特に適しています。継続的テストにより、問題が早期に発見され、バグの蓄積が減り、長期的な修正。 5.5. 協力と透明性を改善したいプロジェクト Continuous Testingは、開発、運用、テストチーム間の協力文化を改善したい組織に適しています。テスト結果が透明化されることで、チームのすべてのメンバーがソフトウェアの品質を監視し、迅速な意思決定を行うことができます。 これにより、衝突が減少し、コミュニケーションが改善され、全体の生産性が向上します。Continuous Testingは単なる技術ツールではなく、品質文化を育む開発戦略の一部でもあります。 5.6. データ駆動型開発と継続的改善を目指すプロジェクト 継続的改善やソフトウェア開発プロセスの最適化を目指すプロジェクトは、Continuous Testingから大きな恩恵を受けます。継続的テストの結果から得られるデータは、組織がバグ傾向を分析し、設計上の弱点を特定し、開発プロセスを調整するために活用されます。これにより、Continuous Testingは単なる品質管理ツールにとどまらず、データに基づく意思決定を支援し、パイプラインの効率を最適化し、変化への適応能力を向上させるツールとなります。 5.7. ユーザー体験の最適化を目指す場合 Continuous Testingは、ソフトウェアがユーザーに届く前に安定して機能することを保証します。プロジェクトがユーザー体験の向上、バグの発生低減、ブランドの信頼維持を目的とする場合、Continuous Testingは重要なソリューションとなります。機能、パフォーマンス、UIに関するバグを早期に検出することで、組織は顧客からのネガティブなフィードバックを回避し、ユーザー満足度を向上させることができます。 結論 Continuous Testingは、DevOpsを適用する際の重要な要素です。テストが不可欠なプロセスとなることで、ソフトウェアはより迅速に開発され、高品質でバグが少なく、ユーザーのニーズに応えることができます。Continuous Testingは、テストを開発サイクルの終盤の段階から、すべてのコード変更に伴う継続的な行動に変えます。 もし、DevOpsプロセスの構築、Continuous Testingの統合、自動化パイプラインの導入を専門家とともに行いたい場合、TCOMは支援の準備ができています。経験豊富なエンジニアチームが、コンサルティング、パイプライン設計、自動テスト作成から導入、保守までサポートします。今すぐTCOMに連絡して、無料相談を受け、ソフトウェア開発プロセスをアップグレードしてください。 続きを読む:

スピードが優位性を決定する時代において、新製品を開発しようとするあらゆる企業は、リソース、コスト、時間、柔軟性に関する課題に直面する。市場の急速な変化と高い競争レベルにより、従来の開発モデルは重く非効率になり、変化に追いつきにくくなる。このような状況で、アウトソーシングは企業が運営を最適化しながら製品の市場投入までの時間を大幅に短縮するための戦略的な解決策となる。 アウトソーシングとは、簡単に言えば企業が業務の一部または全部を外部の専門機関に委託することである。単純作業にとどまらず、今日のアウトソーシングは大きく発展し、技術プロジェクトの実施、製品開発、マーケティング運営、カスタマーサポート、その他多くの複雑な分野において有効な手法となっている。経験豊富なチームによる専門リソースを活用することで、多くの企業が困難な時期を乗り越え、製品ポートフォリオを拡大し、より迅速な成長を実現している。 採用に時間をかけずに専門知識へアクセスする 企業が製品を拡大しようとする際、最大の課題の一つは高度な専門スキルを持つ人材の採用と維持である。新製品の開発は優れたアイデアや魅力的なデザインだけではなく、多くの分野の緻密な連携が必要となる。例えば、技術製品の場合、以下のような人材が求められることが多い。 * プログラマー、テスター、UX/UI 専門家、プロジェクトマネージャー。 * 場合によってはデータや人工知能の専門家。 社内チームを構築するには大きなコストと長い採用期間が必要であり、特に希少な専門職や市場で新しいスキルを持つ人材の採用は困難である。 社内採用なしで即座に専門家にアクセス アウトソーシングは柔軟な解決策を提供する。 * 複雑な採用プロセスを経ずに質の高いリソースへすぐにアクセスできる。 * パートナーの専門知識と実戦経験により、製品の研究、テスト、実装の時間を短縮できる。 * アジャイル、スクラム、デブオプスなどの手法を用いることで、より速く開発し、ミスを減らし、変化に適応しやすくなる。 その結果、企業は採用時間を節約し、プロジェクトの品質、効率、柔軟性を向上させることができる。 プロジェクトの需要に応じてリソースを柔軟に拡大または縮小する アウトソーシングの重要な利点の一つは、リソースを柔軟に調整できることであり、これにより企業は市場の変動やプロジェクトのニーズに迅速に対応できる。新製品を開発する際、人材需要は常に一定ではない。アイデア段階や市場調査段階では少人数の専門チームで十分な場合がある。しかし、開発、テスト、発売準備の段階に入ると、プログラマー、品質エンジニア、UX/UI 専門家、マーケティングチーム、カスタマーサポート、オペレーションの需要が急増することがある。社内リソースだけに依存すると、必要なタイミングでの人員増減が難しく、採用や研修に時間とコストがかかり、管理負担も大きくなる。 アウトソーシングはこの問題を効果的に解決する。すでに専門チームを持ち、技術作業や運用、製品開発をすぐに実施できる外部パートナーと協力することで、企業は迅速にリソースを拡大できる。これはバージョンごとの製品開発や季節性のあるプロジェクト、あるいは複数の新製品を同時にテストしたい場合などに特に重要である。 また、リソースを縮小できる点も大きな強みである。製品が安定した後や発売段階が終了した後にアウトソーシングを減らすことで、企業は運営コストを最適化できる。社内リソースの場合、人員削減には補償や士気への影響、再構築の長期化などのリスクが伴うが、アウトソーシングならこれらを回避でき、新しいプロジェクトに集中しやすくなる。 さらに、リソースの柔軟性はリスク管理にも役立つ。社内チームを構築する場合、新プロジェクトへのリソース投入は失敗リスクや方向転換リスクを常に伴う。アウトソーシングなら必要な時だけリソースを使用でき、状況に応じて迅速に調整できるため、企業は複数の製品アイデアをテストしやすくなり、市場の新しいニーズにも負担なく対応できる。 競合他社が人材採用と教育に数ヶ月を要する一方で、アウトソーシングを活用する企業は専門チームを即座に投入でき、製品をより早く市場に投入できる。このスピードは市場機会の獲得や顧客体験の向上に直結する。 専門性の柔軟性もアウトソーシングの利点である。例えば、AI やビッグデータ分析、ブロックチェーン開発など特別なスキルが必要な場合、企業は数ヶ月も採用や社内研修を行うことなく外部の専門家へすぐにアクセスできる。プロジェクトの各段階で必要なスキルが変わる際も企業は柔軟にリソースを調整でき、効率とコストを最適化できる。 コストを最適化し核心業務に再投資する コストは企業の製品開発と拡大の能力に大きな影響を与える要素である。社内だけで製品を開発する場合、採用や研修費、給与、福利厚生、インフラ、ソフトウェア、設備、システム保守、プロジェクト管理など多くの固定費と変動費が発生する。これらは多くのリソースを消費し、特に中小企業にとって大きな負担となる。新製品開発では予期せぬ費用が発生することが多く、技術的問題や要件変更により計画を超えることもある。 アウトソーシングはコスト最適化の有効な方法を提供する。フルタイムの人材を雇う代わりに、企業はプロジェクト期間中必要なサービスにのみ料金を支払えばよい。これにより固定費が削減され、人件費やインフラコスト、管理費がプロジェクトの需要に応じた変動費へと変わる。企業はサービスが提供する直接的な価値のみを支払えばよく、製品成果に直接関与しないコストへの投資を避けられる。 さらに、節約したリソースを企業の核心業務に再投資できることも大きな利点である。アウトソーシングによって補助業務の運営コストを減らすことで、企業は研究開発、製品の改善、顧客体験の向上、市場拡大、ブランド構築など長期的価値を生む活動に集中できる。 アウトソーシングによるコスト最適化は財務リスク管理にも役立つ。実際の需要に応じて調整される柔軟な費用構造により、企業は費用の急増を避けられ、プロジェクトが失敗した場合でも資源の無駄を抑えられる。 また、企業は外部パートナーの高度な専門知識を活用でき、内部人材の育成に時間やコストを投資する必要がない。これによりコスト削減だけでなく、製品品質の向上、エラーの減少、市場競争力の向上につながる。社内スタッフは深い専門スキルを必要とする作業から解放され、より戦略的で価値の高い業務に集中できる。 インフラや技術に関するコストもアウトソーシングで最適化できる。自社開発の場合、ソフトウェア、サーバー、設備、ライセンス、システム保守などへの投資が必要だが、アウトソーシングではこれらの多くを外部パートナーが負担するため、企業はサービス料金のみ支払えばよい。初期投資の圧力が軽減され、本当に競争優位を生む分野に資金を集中できる。 アウトソーシングを導入した多くの企業は、大幅なコスト削減だけでなく、製品拡大のスピード向上、マーケティングの効果強化、顧客体験向上、市場拡大などに節約した資金を再投資し、正の循環を生み出している。 市場投入までの時間を短縮する 競争環境では早く市場に投入された製品が大きな優位性を持つ。顧客は選択肢が多く、忍耐力が少ないため、ニーズに迅速に応える製品は有利になる。一方、開発が長引くと機会を逃すだけでなく、競合に追い越され、市場シェアや利益の減少につながる。このため、製品の市場投入までの時間短縮は現代の製品開発戦略における最優先事項となっている。 迅速に開発し、製品を早期に発売して市場での優位性を確保 アウトソーシングはこの目標を達成する強力な手段である。社内開発では、人材採用や研修、プロセス構築、ソフトウェアやインフラの調達、プロジェクト管理フレームワークの準備などに多くの時間が必要となる。これらは数ヶ月から数年かかることもあり、市場投入の遅延を引き起こす。アウトソーシングを利用すれば、企業はすぐに経験豊富で標準化されたプロセスを持つチームへアクセスでき、準備段階を大幅に短縮できる。 また、専門経験と標準化されたワークフローも重要である。アウトソーシングパートナーはアジャイル、スクラム、デブオプス、継続的インテグレーション、継続的テストなどの最新手法を採用していることが多い。これらは開発プロセスを最適化し、ミスを減らし、要件変更への対応力を高め、開発スピードを向上させる。 必要な時期に短期間で大量のリソースを動員できる点も重要である。社内リソースだけに依存すると人材と専門性の限界により開発が遅れる可能性があるが、アウトソーシングのチームはプロジェクトの段階に応じて人員を迅速に拡大または調整でき、新機能開発、テスト、ユーザー体験設計、デジタルマーケティングなどを並行して実施できる。これは特にユーザーのフィードバックに基づく継続的な更新が必要な技術製品において重要である。 アウトソーシングは試行錯誤の時間を削減する点でも有利である。社内経験が不足している場合、設計やプログラミング、テストにおいて多くのミスが発生し、修正や最適化のために時間がかかる。アウトソーシングでは類似プロジェクトを経験した専門家が迅速に問題を解決でき、無駄な時間を減らすことができる。 さらに、市場や顧客のフィードバックに対する対応スピードも向上する。早期に製品を市場へ投入することで企業はすぐに意見を収集し、改善を加え、競争力を強化できる。 市場投入までの時間短縮はスピードだけでなく財務効果ももたらす。早期に製品を売り出すことで収益を生み出し、顧客データを取得し、マーケティング戦略を迅速に最適化できる。 リスクを減らし製品品質を保証する 新製品開発には採用リスク、技術リスク、スケジュールリスク、運用リスクなど多くのリスクが伴う。経験不足の社内チームではこれらのリスクが増大し、重大なミスやプロジェクト失敗につながりやすい。 アウトソーシングは多くの類似プロジェクトに対応してきた経験豊富なチームによってリスクを低減する。プロジェクト管理手法、テストモデル、品質管理プロセス、進捗管理ツールなどに精通しており、専門的な基準を用いることで製品の安定性を高め、リリース後の問題を減らせる。 さらに、多くの信頼できるアウトソーシング企業は契約において品質、スケジュール、セキュリティについて明確にコミットしており、企業のリスク管理負担を軽減する。 コア戦略により集中する 社内開発を行う企業が忘れがちな点は、リソースの分散である。技術、運用、実装など大量の業務を抱えることで、ユーザー調査、ブランド構築、製品戦略、市場拡大といった戦略的活動に十分な時間とエネルギーを割けなくなる。 アウトソーシングは運用負担の大部分を軽減し、企業が長期的ビジョンと戦略、創造活動に最大限集中できるようにする。継続的なイノベーションが求められる企業や短期間で製品ラインを拡大したい企業において特に重要である。強力な技術チームの支援があれば、社内人員を増やさずとも多くのバージョンや製品ラインを生み出せる。 まとめ アウトソーシングは単なるコスト削減手段ではない。これは企業が製品開発を加速し、ビジネスポートフォリオを拡大し、リスクを削減し、品質を維持し、社内リソースを最適化するための戦略的なツールである。高度な専門知識へのアクセス、柔軟なチーム拡大能力、標準化されたワークプロセスにより、アウトソーシングはもはやスピードを求めるすべての企業にとって大きな優位性となる。 市場が日々変化する時代において、対応が遅れる企業は機会を失う。信頼できるアウトソーシングパートナーとの協力は、製品の迅速な市場投入だけでなく、長期的成長のための確かな基盤づくりに貢献する。 TCOM は製品開発、プログラミング、デジタルトランスフォーメーション、技術ソリューションコンサルティング、運用最適化において実戦経験を持つ信頼できるアウトソーシングサービスプロバイダーである。経験豊富な専門家チームと国際標準のワークプロセスにより、TCOM は企業の製品市場投入時間を短縮し、品質と投資効果を確保する。 製品開発を加速し、リソースを最適化し、市場を拡大するためのパートナーを探している場合は、ぜひ TCOM に問い合わせ、あなたの企業に最適なソリューションを相談してほしい。 続きを読む:
 お問い合わせ
お問い合わせ